Are train-test splits for model evaluation in the ML pipeline must?
Covering the basics of the machine learning series, in this article I argued why we need to process data in silos to freeze a model for production.

As a passionate Machine Learning and Deep Learning enthusiast, I document my learning journey on Hashnode. My experience encompasses various projects, from exploring foundational algorithms to implementing advanced neural networks. I enjoy breaking down complex concepts into digestible insights, making them accessible for all. Join me as I share my thoughts, tutorials, and tips to navigate the exciting world of ML and DL. Connect with me on LinkedIn to explore collaboration opportunities!
This article looks at the purpose, methods, and limitations of splitting a dataset into training and test sets that are commonly used in machine learning. Further, I argue why one should refrain from using it directly. Splitting methods generally preserve the statistical properties of the original dataset and are assumed not to introduce bias to the outcome.
In general, data preparation is the most time-consuming affair in the whole machine learning (ML) pipeline. Foremost, the raw data is refined enough to feed into the ML pipeline. Such polished data further needs to be prepared in order to get a model ready, which would further be deployed into production. Ok. So, to be clear, there are two broad phases. First, model preparation, and second model deployment. In this blog, I will concentrate only on the first part, the model preparation.
The 'split' into 'train-test'
The whole dataset which is refined for the ML pipeline needs to be split into a training set and a test set (at least). The benefits - the test accuracy will be good. As the model developed on the training data set (seen) will be applied to the test data set (unseen) for model performance evaluation. This is done to strengthen the belief that the model, thus, developed is competent enough to be ready for deployment in the second phase. Of course, if and only if the model performs well too on test sets. On a side note, the score of the model generally depends on the way such splits are done. Also, the train-test splits are made only once.
The train-test split goal
The train-test split problem is the problem of splitting a dataset into two parts, one part to be used for training and the other for testing. The split is usually done once and for all. The training and test sets are used to develop a model that may be used in the production state to solve a given problem. The goal of the splitting process is to split the dataset in such a way that the resulting model will be fair and valid and that it did not introduce bias.
Reasons to split datasets
There are mainly three reasons to split a dataset.
1. First and foremost is to avoid overfitting.
A dataset is split into two parts, viz. a training set, and a test set. For instance, the training set is used to train a model. While the test set is used to test the model on data that it has not seen. Thus, the model is trained only on the training set, and its performance is evaluated only on the test set. This process helps avoid overfitting and gives a good idea of how well the model will generalize to new data.
2. The next motivation is to estimate the expected performance of a model.
To estimate the expected performance, it is necessary to average the result after testing the model on many different test sets. This, however, in general, is very time-consuming. Therefore, a single test set is used. Also, it must be noted that the test set should be representative of the data the model is expected to see in the future. Furthermore, if the test set is not representative of future data, the results of the test would not be accurate.
3. The last but not least reason is to compare two or more models.
In order to compare models, it is good to test them on the same test set. However, the test set must be representative of the data the model is expected to see in the future.
Why splitting so difficult
Splitting a dataset is difficult because the same data set can be used to build many different models. A single split of the data will be good for some models, but not for others. In order to get good models, the split must also be good for all models. Statistically, thus the split must preserve -
- the distribution of the target.
- the distribution of the features.
- the distribution of the target and the features.
- the distribution of the features given to the target.
- the distribution of the target-given features.
- the joint distribution of the features and the target.
- the joint probability distribution of the features and the target.
- the conditional probability distribution of the target given the features.
- the joint distribution of the features and the target, and the conditional distribution of the target given the features.
- the joint distribution of the features and the target, and the conditional distribution of the features given the target.
- the distribution of the target and the features, and the conditional distribution of the target given the features.
- the distribution of the target and the features, and the conditional distribution of the features given the target.
The problem with the 'split'
On large datasets, it won't be a problem, but what about smaller datasets, say from the medical domain? Will the trained model be qualified enough for production mode? So, this gives rise to the downside of the train-test split, namely -
- Single split doesn't give any information about variability,
- In a setting with small data sets, the amount of data available for training and testing will be much smaller after splitting, making the model unreliable for production.
Therefore, this seems to be a big caveat. The job of a data scientist doesn't end with model evaluation on the test data set. He/she must also ensure the model qualifies to be put into use, safely. Safely into production. Consequently, is there any solution to this caveat?
Existing methods of splitting the datasets and their respective issues
Before running an algorithm, the data needs to be split into training and test sets. The following are the existing methods available to split a data set for machine learning -
1. Random Split
In random split, the dataset is split randomly into training and test sets. The training set contains 80% of the data, and the test set contains 20% of the data. This split helps to test the algorithm and see how it performs on a new dataset.
Random split into training and test sets do not stand representative of the whole dataset. The training set might have many examples of one class, and the test set might have many examples of another class. In such a case, the model might be able to achieve high accuracy on the test set, but might not be able to generalize to new data. And this seems to be a big drawback.
2. Stratified Split
To overcome the limitation of the random split, the stratified split came into existence. A stratified split ensures that each set (train and test) is representative of the whole data set. Here, in a stratified split, the data is divided such that each set contains the same proportion of each class. For example, if we have 1000 patients, of which 100 have the disease, then the training and test sets should also have 100 patients each with the disease. Stratified splits, thus also ensure that the training and test sets contain the same proportion of each class label.
3. Train-Test Split
The stratified split method is better than the random split method. However, the stratified split method does also have limitations. Dividing the data into 80% training and 20% test, results in 80% training data, and the remaining 20% test data. When all the data is needed to train the model, and none of the data is for testing, a train-test split is used. Thus, in a train-test split, all the data is used for training and none of the data for testing. However, some of the data for testing is used by using cross-validation. In a train-test split, the data is divided into two sets. While using one set for training, the other for testing, and using cross-validation to estimate the accuracy of the model.
For instance, suppose there are 1000 patients, of which 100 have a disease. All the data is used to train the model, using a train-test split. The first set contains 800 patients, and the second set contains 200 patients. The first set is used for training and the second set is for testing. Further, cross-validation is used to estimate the accuracy of the model. Divide the first set into 10 folds and use 9 folds for training, and 1-fold for testing. This process is repeated until each fold has been used for testing. The average accuracy of the test folds as an estimate of the accuracy of the model is used.
4. Cross-validation
In cross-validation, a part of the data is used to train the model, and the other part to test it. This process is repeated until every part of the data has been used for training and testing. The average accuracy of the test sets is then used as the estimate of the accuracy of the algorithm.
This method, however, is not suitable for a final test. If, for instance, split the data into 10 sets, then only use 90% of the data to train the model. On a small dataset, the model will not be very accurate. The accuracy of the test sets will be low, and whether the algorithm will work well on a new dataset or not, will not be known. However, this is not true with larger datasets.
Why 'split' in the first place?
Before arguing for solutions, I feel intuitive to discuss why in the first place the split is needed at all. The whole purpose of splitting data before training the model is to assess the generalization performance of the model. The generalization model, in the data scientist world, is also known as predictive performance, statistical performance, or even computational performance.
During building a machine learning model, it was realized that it is not a good idea to evaluate the trained model on the data that was used to fit the model, for its generalization. (Generalization in simple terms means a rule that generalizes to new data without comparing the used data, as it is harder to conclude on never-seen instances than on already-seen ones)
How to implement train-test split - an illustration
After a brief discussion on the benefits and drawbacks of different splitting methods, now let's see how to implement them. It can be implemented by using a random split in the train_test_split method from scikit-learn. This method is used to split the dataset into training and test sets. Here, it is necessary to specify the random state that sets the random seed.
The need for train-test split
Let's first understand why a train-test split is needed. Suppose there is a dataset with 1000 data points. Now, this dataset is needed to train a model. However, in machine learning, the whole dataset to train a model is never used. The reason is that machine learning models are not perfect. They usually have a certain level of error. If the whole dataset to train the model is used, it would be able to get a model that perfectly fits the data. However, this model may not be able to predict the output for new data points (data points that are not in the dataset). This is called overfitting. Therefore, instead of using the whole dataset to train the model, usually, the dataset is split into two subsets:
- Training Set: This is a subset of the dataset used to train the model.
- Test Set: This is a subset of the dataset used to test the model.
Then train the model using the training set and test the model using the test set.
Implementation
The train-test split is implemented using the train_test_split function in the sklearn.model_selection module.
The function has the following parameters:
X: A data frame or a NumPy array. The data frame or array containing the features.
y: A data frame or a NumPy array. The data frame or array containing the target variable.
test_size: The percentage of data points in the test set.
train_size: The percentage of data points in the training set.
random_state: A number. The random seed.
Split the dataset using
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
Using the Wine Quality dataset from the UCI Machine Learning Repository and using the quality variable as the target variable. Also using the fixed acidity, volatile acidity, citric acid, residual sugar, chlorides, free sulfur dioxide, total sulfur dioxide, density, pH, and sulphates variables as the features.
Load the dataset -
from sklearn.datasets import load_wine
wine = load_wine()
Examine the dataset -
wine.head()
Split the dataset -
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
wine.data, wine.target, test_size=0.2, random_state=42)
Examine the training set
X_train.head()
Examine the test set
X_test.head()
Use the training set to train a linear regression model and use the test set to test the model -
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, y_train)
y_pred = lr.predict(X_test)
Examine the model's performance on the test set -
from sklearn.metrics import mean_squared_error
print(f'Mean squared error: {mean_squared_error(y_test, y_pred):.2f}')
The mean squared error is 0.198, hence, this model's performance is not perfect. The reason is that the model is not able to capture all the information in the training set. Some features might be correlated with the target variable and the model is not able to find it. This may be a good example of underfitting and this model may perform better if a more complicated model is used.
The generalization processes
Accordingly, for generalization, the correct evaluation warrants an entirely new and unseen but similar data set. So, a portion of the data set is left out as a subset of the data in the memory itself, before training the model. Afterward, the left-out dataset is used to evaluate the model for generalization. In machine learning terminology, this evaluation is represented as score.
Thus, the whole idea is to fit, then predict to get a score for the model, which is central to the train-test split. Let's explore these a little bit in depth to get a fair idea of what and why we are doing so.
The 'fit' process
The model fit is done on features (training data) and the target (training) of the dataset. The fit method is composed of the -
- learning algorithm
- model states
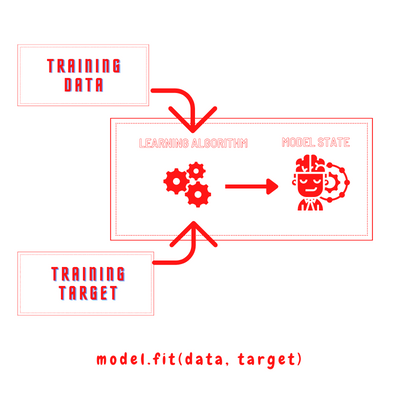
The learning algorithm takes the training data and training target as input and sets the model state. These model states are used to -
- predict (for classification and regression)
- transform data (for transformers)
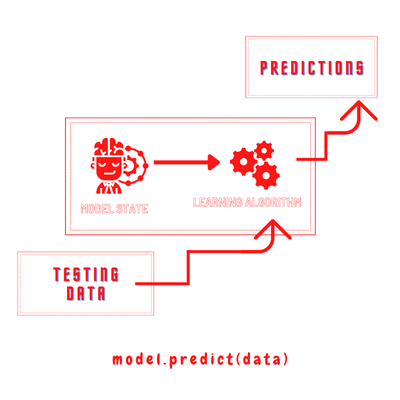
The 'predict' process
Here, the model uses a prediction function. It uses the input (test) data with the model state generated from the model.fit(data, target). Please note that for each learning algorithm and model state, the prediction function is unique.
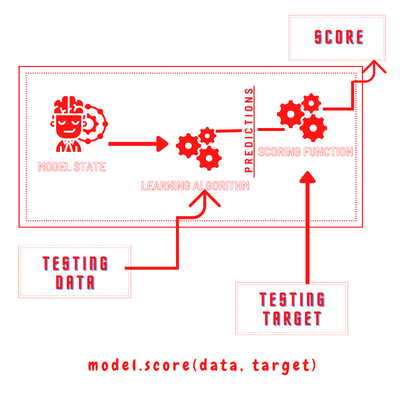
The 'score' process
Using the predict function from above, predictions are computed and then a score function is used to compare true targets with the predicted one, to get the score.
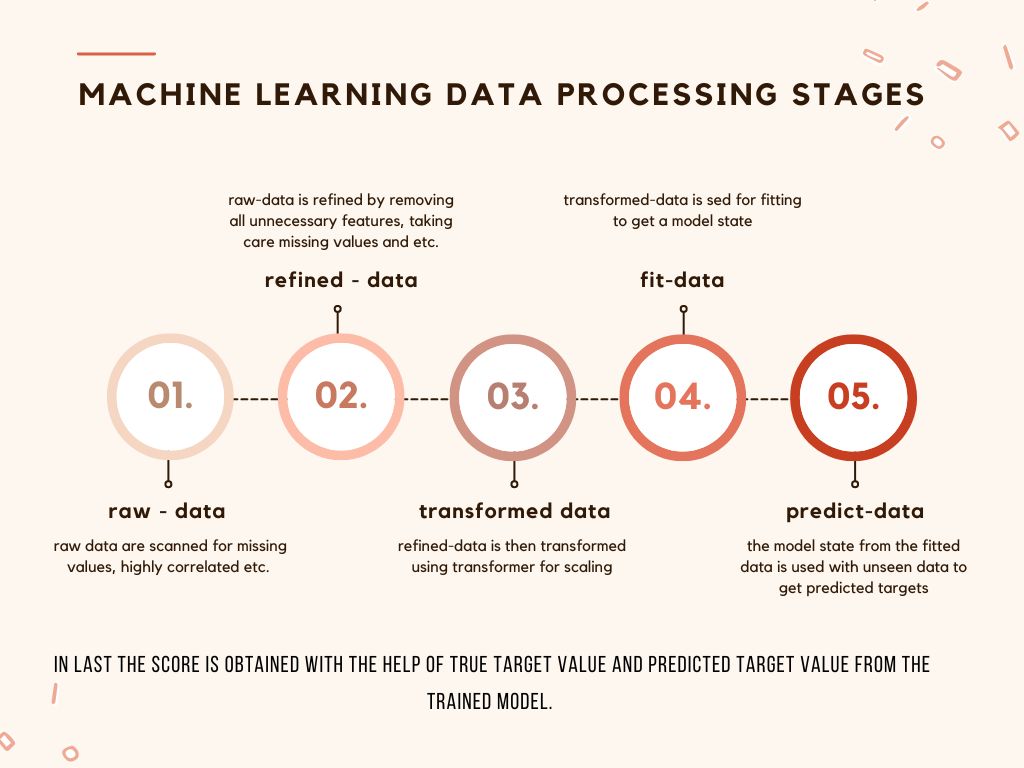
The data 'process' stages
Now we are in a comfortable position to assess the whole data 'process' stages in a machine learning pipeline meant for production. First, the fit is done on seen data, the predict on unseen data, and the score uses targets from unseen data and the predicted targets from unseen data. Here is the catch. Data scientists generally use a random seed to split the data into train-test sets once. The test set is used for the model evaluation, believing bias to be mitigated. But the bias remains, as explained above while discussing the downside of train-test split.
Furthermore, for scaling purposes, in place of raw data, scaled data is used to fit the model. All features of data sets are scaled individually using transformers. This is another quite important preprocessing technique. So, the data processing for machine learning actually goes like this -
Closing argument and remarks - 'pipeline' and 'cross-validation'
As from the above, we noted that almost 6 stages are there to get a model that stands ready to be used in production. However, scikit-learn a framework in machine learning provides two APIs to ease these 6 stages of the task. They are pipeline and cross-validation. The pipeline API takes care of the data preparation till the predict-data stage and the cross-validation for the optimal score of the model. Cross-validation uses part of the data to train the model, and the other part to test it. This process is repeated until every part of the data has been used for training and testing. The average accuracy of the test sets is then used as the estimate of the accuracy of the algorithm. Both are the concepts I will be covering in my next blog article.
References -




